背景
为什么会想研究这个“很小的”问题,起因是笔者参与的公司某项目将查询参数保存到URL,设置多个查询条件后,URL链接一共包含1840个字符(占用1840字节),这样的过长的URL使用时是否存在风险?网上关于URL最大长度的搜索结果普遍是URL不超过2048,种种结论是否有可信出处?近几年随着互联网标准、浏览器、服务器更新迭代,是否有变化?本文从互联网标准原文、浏览器、服务器源码入手,一探究竟。
本文涉及大量琐碎的外部内容引用,是笔者有意为之,如果想直接知道结果,可以翻看文末的【思考总结】。
HTTP和URI标准是否对URL长度有限制
HTTP 消息的组成
HTTP/1.1
HTTP/1.1的消息语法格式定义于 RFC 7230 Hypertext Transfer Protocol (HTTP/1.1): Message Syntax and Routing 标准。 以下是 HTTP消息的部分语法描述(ABNF形式):
HTTP-message = start-line
*( header-field CRLF )
CRLF
[ message-body ]
start-line = request-line / status-line
request-line = method SP request-target SP HTTP-version CRLF
status-line = HTTP-version SP status-code SP reason-phrase CRLF
request-target = origin-form
/ absolute-form
/ authority-form
/ asterisk-form
origin-form = absolute-path [ ? query ]
absolute-form = absolute-URI
authority-form = authority
asterisk-form = * ABNF 全称 Augmented Backus–Naur form(扩充巴科斯范式),不仅能严格地表示语法规则,而且所描述的语法是与上下文无关的。它具有语法简单,表示明确,便于语法分析和编译的特点。
HTTP/1.1消息示例:
GET http://localhost:8080/?name=foo&value=bar HTTP/1.1POST http://localhost:8080/ HTTP/1.1
Content-Type: application/json;charset=utf-8
{ name : foo , value : bar }HTTP 请求行
HTTP 标准没有预定义 HTTP 请求行的长度,但提到实践中存在限制,推荐所有的 HTTP 发送方和接收方至少支持 8000 字节(7.8125 KB)。
HTTP does not place a predefined limit on the length of a request-line, as described in Section 2.5. A server that receives a method longer than any that it implements SHOULD respond with a 501 (Not Implemented) status code. A server that receives a request-target longer than any URI it wishes to parse MUST respond with a 414 (URI Too Long) status code (see Section 6.5.12 of [RFC7231]).
Various ad hoc limitations on request-line length are found in practice. It is RECOMMENDED that all HTTP senders and recipients support, at a minimum, request-line lengths of 8000 octets.
HTTP/2
相对于文本形式的 HTTP/1,HTTP/2 改为使用二进制表示,一个 HTTP 消息由多个帧组成(见 RFC 7540)。
An HTTP message (request or response) consists of:
- for a response only, zero or more HEADERS frames (each followed by zero or more CONTINUATION frames) containing the message headers of informational (1xx) HTTP responses (see [RFC7230], Section 3.2 and [RFC7231], Section 6.2),
- one HEADERS frame (followed by zero or more CONTINUATION frames) containing the message headers (see [RFC7230], Section 3.2),
- zero or more DATA frames containing the payload body (see [RFC7230], Section 3.3), and
- optionally, one HEADERS frame, followed by zero or more CONTINUATION frames containing the trailer-part, if present (see [RFC7230], Section 4.1.2).
帧的格式如下图所示,每个二进制帧都由固定9字节长度的 Header 和不定长的 Payload 组成:

帧的 Payload 大小由接收方通过 SETTINGS_MAX_FRAME_SIZE 设置(虽然帧有大小限制,但一个 HTTP 消息由多个帧组成,所以不影响 HTTP 消息大小)。
The size of a frame payload is limited by the maximum size that a receiver advertises in the SETTINGS_MAX_FRAME_SIZE setting. This setting can have any value between 2^(14) (16,384) and 2^(24)-1 (16,777,215) octets, inclusive.
All implementations MUST be capable of receiving and minimally processing frames up to 2(14) octets in length, plus the 9-octet frame header (Section 4.1). The size of the frame header is not included when describing frame sizes.
另外在 HTTP/2 的消息中不再有请求行,而是采用伪首部字段(Request Pseudo-Header Fields)表示:
- :method HTTP方法
- :scheme 目标URL协议
- :authority 目标URL认证部分
- :path 目标URL的路径和查询部分
- :status HTTP状态码
HTTP/2 伪首部示例:
:authority: localhost:8443
:method: GET
:path: /?name=foo&value=bar
:scheme: https鉴于 HTTP/2 没有请求行,所以伪首部的大小不受 HTTP/1.1 推荐的 8000 字节影响。
HTTP 响应码
HTTP 标准针对服务器实现给出了URL过长、请求头太大、负载太大相关HTTP 响应码定义:
- 413 Payload Too Large
The 413 (Payload Too Large) status code indicates that the server is refusing to process a request because the request payload is larger than the server is willing or able to process. The server MAY close the connection to prevent the client from continuing the request.
If the condition is temporary, the server SHOULD generate a Retry-After header field to indicate that it is temporary and after what time the client MAY try again.
- 414 URI Too Long
The 414 (URI Too Long) status code indicates that the server is refusing to service the request because the request-target (Section 5.3 of [RFC7230]) is longer than the server is willing to interpret. This rare condition is only likely to occur when a client has improperly converted a POST request to a GET request with long query information, when the client has descended into a "black hole" of redirection (e.g., a redirected URI prefix that points to a suffix of itself) or when the server is under attack by a client attempting to exploit potential security holes.
A 414 response is cacheable by default; i.e., unless otherwise indicated by the method definition or explicit cache controls (see Section 4.2.2 of [RFC7234]).
- 431 Request Header Fields Too Large
The 431 status code indicates that the server is unwilling to process the request because its header fields are too large. The request MAY be resubmitted after reducing the size of the request header fields.
It can be used both when the set of request header fields in total is too large, and when a single header field is at fault. In the latter case, the response representation SHOULD specify which header field was too large.
URL的组成
URL的标准包括 RFC 1738 Uniform Resource Locators (URL) 和 RFC 3986 Uniform Resource Identifier (URI): Generic Syntax ,后者是前者的超集,用于标识网络上的资源。以下是URI的部分语法描述(ABNF形式):
URI = scheme : hier-part [ ? query ] [ # fragment ]
hier-part = // authority path-abempty
/ path-absolute
/ path-rootless
/ path-empty
URI-reference = URI / relative-ref
absolute-URI = scheme : hier-part [ ? query ]
relative-ref = relative-part [ ? query ] [ # fragment ]
relative-part = // authority path-abempty
/ path-absolute
/ path-noscheme
/ path-empty
scheme = ALPHA *( ALPHA / DIGIT / + / - / . )
authority = [ userinfo @ ] host [ : port ]
userinfo = *( unreserved / pct-encoded / sub-delims / : )
host = IP-literal / IPv4address / reg-name
port = *DIGIT
path = path-abempty ; begins with / or is empty
/ path-absolute ; begins with / but not //
/ path-noscheme ; begins with a non-colon segment
/ path-rootless ; begins with a segment
/ path-empty ; zero characters
path-abempty = *( / segment )
path-absolute = / [ segment-nz *( / segment ) ]
path-noscheme = segment-nz-nc *( / segment )
path-rootless = segment-nz *( / segment )
path-empty = 0<pchar>
segment = *pchar
segment-nz = 1*pchar
segment-nz-nc = 1*( unreserved / pct-encoded / sub-delims / @ )
; non-zero-length segment without any colon :
pchar = unreserved / pct-encoded / sub-delims / : / @
query = *( pchar / / / ? )
fragment = *( pchar / / / ? )
pct-encoded = % HEXDIG HEXDIG
unreserved = ALPHA / DIGIT / - / . / _ / ~
reserved = gen-delims / sub-delims
gen-delims = : / / / ? / # / [ / ] / @
sub-delims = ! / $ / & / ' / ( / )
/ * / + / , / ; / = 一个简单示例:
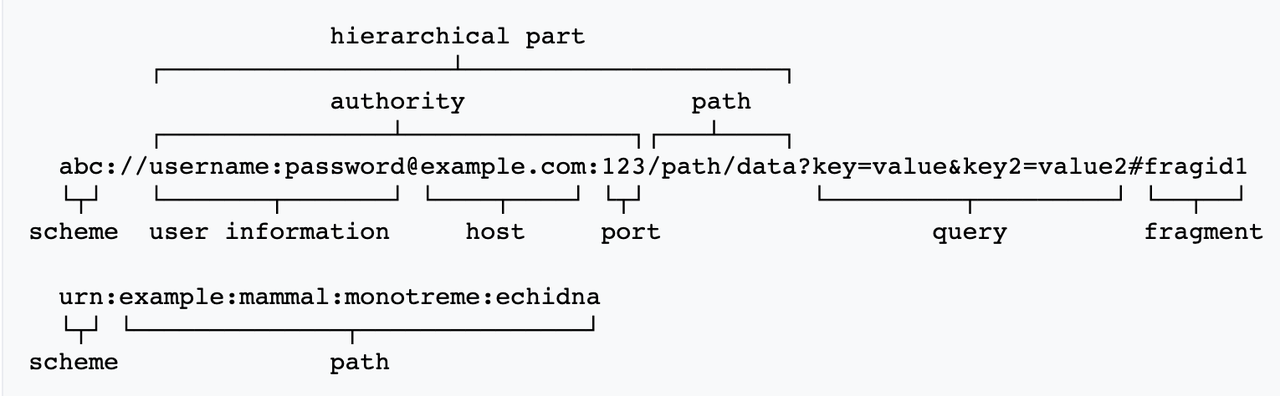
URL编码
RFC 1738 除了对URL的语法做出了严格定义,还对字符集和编码进行了说明:
URLs are written only with the graphic printable characters of the US-ASCII coded character set. The octets 80-FF hexadecimal are not used in US-ASCII, and the octets 00-1F and 7F hexadecimal represent control characters; these must be encoded.
Thus, only alphanumerics, the special characters $-_.+!*'(), , and reserved characters used for their reserved purposes may be used unencoded within a URL.
When a new URI scheme defines a component that represents textual data consisting of characters from the Universal Character Set [UCS], the data should first be encoded as octets according to the UTF-8 character encoding [STD63]; then only those octets that do not correspond to characters in the unreserved set should be percent- encoded.
URL只能使用US-ASCII字符集中的可打印字符。除字母、数字、一些特殊符号和保留字以外,其余都必须进行编码。数据在进行百分号编码时使用UTF-8编码。
以汉字“中”为例看URL如何编码
首先确认“中”字在Unicode中的码点,即U+4E2D。
'中'.codePointAt(0).toString(16).toUpperCase(); // '4E2D'然后在Unicode的Unihan数据库中查找 U+4E2D 对应的 UTF-8 编码 https://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=4E2D

即 0xE4 0xB8 0xAD,最后“中”字百分号编码为 %E4%B8%AD,对应 encodeURIComponent() 执行结果。
encodeURIComponent('中'); // '%E4%B8%AD'由于中文汉字全部超出 US-ASCII 字符集(CJK基本区 U+4E00~U+9FEF,CJK扩展A区 U+3400~U+4DB5),在Unicode中码点最小的汉字“㐀(U+3400)”转成UTF-8也需要3位:0xE3 0x90 0x80,百分号编码后共占用9字节,可见如果在URL中拼接中文参数会使得URL长度快速增长。
Web浏览器和服务器是否对URL长度有限制
在HTTP和URI标准中没有对URL长度做出限制,那么具体到浏览器和服务器的实现呢?
浏览器URL长度限制
Chromium (Chrome/Edge)
Chromium 对 URL 长度的限制为 2*1024*1024=2097152 (2MB)。源码中对应的常量定义于 https://github.com/chromium/chromium/blob/664fa07d1a10cabd8d5138d17e4bb4cc1edaf769/url/url_constants.cc#L61 文件:
const size_t kMaxURLChars = 2 * 1024 * 1024;仅当 URL 长度不超过 kMaxURLChars 时,才会调用 Google 的 URL 解析库 GURL 进行解析。
实测URL超出 2MB 后,Chrome 打开提示 about:blank#blocked,即 2097152 可以打开,2097153 无法打开。可以和以下单元测试对应:
https://github.com/chromium/chromium/blob/c4d3c31083a2e1481253ff2d24298a1dfe19c754/ios/chrome/browser/web/invalid_url_tab_helper_unittest.mm#L60-L79
// Tests that navigation is allowed for https url links if url length is under
// allowed limit.
TEST_F(InvalidUrlTabHelperTest, HttpsUrlUnderLengthLimit) {
NSString* spec = [@ https:// stringByPaddingToLength:url::kMaxURLChars
withString:@ 0
startingAtIndex:0];
auto policy = GetPolicy(spec, ui::PAGE_TRANSITION_LINK);
EXPECT_TRUE(policy.ShouldAllowNavigation());
}
// Tests that navigation is cancelled for https url links if url length is above
// allowed limit.
TEST_F(InvalidUrlTabHelperTest, HttpsUrlAboveLengthLimit) {
NSString* spec = [@ https:// stringByPaddingToLength:url::kMaxURLChars + 1
withString:@ 0
startingAtIndex:0];
auto policy = GetPolicy(spec, ui::PAGE_TRANSITION_LINK);
EXPECT_FALSE(policy.ShouldAllowNavigation());
EXPECT_FALSE(policy.ShouldDisplayError());
}2MB可以存储多少信息?我们可以做个粗略估算,一本简体中文版《三体1》共19.5万字,如果使用URL编码,按一个汉字9字节计算约为1.67MB(作为对比,英文原版《哈利波特与魔法石》共76944字,按一个字母1字节计算只有约75.14KB大小)。由此可见2MB的URL足以容纳一本长篇小说。
Gecko (Firefox)
Gecko 对 URL 长度的限制为 1048576(1MB)。源码中对应的常量定义于 https://github.com/mozilla/gecko-dev/blob/a7d4b256719357f3f5cf89b30285d8a53f4e5d98/modules/libpref/init/StaticPrefList.yaml#L10280-L10284 配置文件:
# The maximum allowed length for a URL - 1MB default.
- name: network.standard-url.max-length
type: RelaxedAtomicUint32
value: 1048576
mirror: alwaysGecko 在解析 URL 时会调用 StaticPrefs::network_standard_url_max_length() 判断长度。
https://github.com/mozilla/gecko-dev/blob/2a0b0ababd4541ecffb74cbe0820a9d0a25da636/netwerk/base/nsStandardURL.cpp#L1144-L1161
nsresult nsStandardURL::ParseURL(const char* spec, int32_t specLen) {
nsresult rv;
if (specLen > (int32_t)StaticPrefs::network_standard_url_max_length()) {
return NS_ERROR_MALFORMED_URI;
}
//
// parse given URL string
//
uint32_t schemePos = mScheme.mPos;
int32_t schemeLen = mScheme.mLen;
uint32_t authorityPos = mAuthority.mPos;
int32_t authorityLen = mAuthority.mLen;
uint32_t pathPos = mPath.mPos;
int32_t pathLen = mPath.mLen;
rv = mParser->ParseURL(spec, specLen, &schemePos, &schemeLen, &authorityPos,
&authorityLen, &pathPos, &pathLen);
// ...WebKit (Safari)
WebKit 目前对 URL 长度无限制,即使是 2MB URL,依然可以打开。URL 解析的代码见 https://github.com/WebKit/WebKit/blob/916450dba904cee84e033a122bf933e5923ac4f3/Source/WTF/wtf/URLParser.cpp#L1101 文件:
void URLParser::parse(const CharacterType* input, const unsigned length, const URL& base, const URLTextEncoding* nonUTF8QueryEncoding)
{
URL_PARSER_LOG( Parsing URL <%s> base <%s> , String(input, length).utf8().data(), base.string().utf8().data());
m_url = { };
ASSERT(m_asciiBuffer.isEmpty());
Vector<UChar> queryBuffer;
unsigned endIndex = length;
if (UNLIKELY(nonUTF8QueryEncoding == URLTextEncodingSentinelAllowingC0AtEndOfHash))
nonUTF8QueryEncoding = nullptr;
else {
while (UNLIKELY(endIndex && isC0ControlOrSpace(input[endIndex - 1]))) {
syntaxViolation(CodePointIterator<CharacterType>(input, input));
endIndex--;
}
}
CodePointIterator<CharacterType> c(input, input + endIndex);
CodePointIterator<CharacterType> authorityOrHostBegin;
CodePointIterator<CharacterType> queryBegin;
while (UNLIKELY(!c.atEnd() && isC0ControlOrSpace(*c))) {
syntaxViolation(c);
++c;
}
// ...Internet Explorer
IE对URL长度限制的情况最为复杂,可以简单认为不超过2083字节。因为IE是闭源软件,所以只能从微软提供的文档中确认相关细节。
- Maximum URL length is 2,083 characters in Internet Explorer 2019-08-01
- URL Length Limits - IEInternals 2014-08-13
从这两份文档可以得知 Windows Internet (WinINet) API 在 WinINET.h 中定义了 INTERNET_MAX_URL_LENGTH,将URL长度限制为32+3+2048=2083字节。
#define INTERNET_MAX_PATH_LENGTH 2048
#define INTERNET_MAX_SCHEME_LENGTH 32
#define INTERNET_MAX_URL_LENGTH (INTERNET_MAX_SCHEME_LENGTH + sizeof( :// ) + INTERNET_MAX_PATH_LENGTH)从IE7开始,微软逐步将旧版基于 WinINet API 的 URL 处理代码迁移到新的 CURI,移除2083长度限制。
| URL | Data URI | Mailto URI | JavaScript URI | Application Protocol URL | UI Limits | |
|---|---|---|---|---|---|---|
| IE7 | 2083字节 | 不支持 | 地址栏只支持2047字节 | |||
| IE8 | 如果配置代理服务器则限制为2083,否则无限制 | 32KB | 512字节 | ~260字节 | 同上 | |
| IE9-IE10 | 无限制 | 无限制 | 512字节 | ~5KB | 同上 | |
| IE11 | 无变化 | 无变化 | 无变化 | 无变化 | 507字节 | 同上 |
服务器URL长度限制
Node.js
Node.js v17 对 URL 长度的默认限制为 16KB(准确的说是 URL、Status Message 和 Headers 共享)。常量定义于 https://github.com/nodejs/node/blob/6ec225392675c92b102d3caad02ee3a157c9d1b7/src/node_options.h#L124
uint64_t max_http_header_size = 16 * 1024;v13.13.0 之前的版本,默认为8KB,见 https://nodejs.org/dist/latest-v17.x/docs/api/cli.html#--max-http-header-sizesize 历史记录。
除了
max_http_header_size的数值变化,Node.js 内部使用的 HTTP 解析器也有变更,v12 以上版本使用基于 TypeScript 的 llhttp 代替了旧版的基于 C 的 http-parser 。
llhttp 暴露了 on_url、on_status、on_header_field、on_header_value 等方法给调用方使用。
const llhttp_settings_t Parser::settings = {
Proxy<Call, &Parser::on_message_begin>::Raw,
Proxy<DataCall, &Parser::on_url>::Raw,
Proxy<DataCall, &Parser::on_status>::Raw,
Proxy<DataCall, &Parser::on_header_field>::Raw,
Proxy<DataCall, &Parser::on_header_value>::Raw,
Proxy<Call, &Parser::on_headers_complete>::Raw,
Proxy<DataCall, &Parser::on_body>::Raw,
Proxy<Call, &Parser::on_message_complete>::Raw,
Proxy<Call, &Parser::on_chunk_header>::Raw,
Proxy<Call, &Parser::on_chunk_complete>::Raw,
// on_url_complete
nullptr,
// on_status_complete
nullptr,
// on_header_field_complete
nullptr,
// on_header_value_complete
nullptr,
};Node.js 的 HTTP parser 在 llhttp 钩子方法中累计 URL、Status Message 和 Headers 长度,超出报Header overflow 错误。 https://github.com/nodejs/node/blob/6a1986d50a8f511ae20eb0cdc32659e67d79852b/src/node_http_parser.cc
uint64_t header_nread_ = 0;
uint64_t max_http_header_size_;
int TrackHeader(size_t len) {
header_nread_ += len;
if (header_nread_ >= max_http_header_size_) {
llhttp_set_error_reason(&parser_, HPE_HEADER_OVERFLOW:Header overflow );
return HPE_USER;
}
return 0;
}
int on_url(const char* at, size_t length) {
int rv = TrackHeader(length);
if (rv != 0) {
return rv;
}
url_.Update(at, length);
return 0;
}
int on_status(const char* at, size_t length) {
int rv = TrackHeader(length);
if (rv != 0) {
return rv;
}
status_message_.Update(at, length);
return 0;
}
// ...nginx
nginx 对 URL 的长度限制和 Node.js 类似,也是URL和请求头共享Buffer大小,请求行默认限制为8KB。具体的工作流程可以参考 Tengine 的文章 Nginx开发从入门到精通:nginx的请求处理阶段 ,其中 ngx_http_process_request_line() 负责处理请求行, ngx_http_parse_request_line() 负责解析请求行,请求头的默认Buffer大小为1KB,可以使用 client_header_buffer_size 指令修改,如果客户端发过来的请求头大于1KB,nginx会重新分配更大的缓存区,默认用于超大请求头的Buffer最大为8KB,最多4个,这两个值可以用 large_client_header_buffers 指令设置。
client_header_buffer_size- 语法:client_header_buffer_size size;
- 默认:client_header_buffer_size 1k;
- 配置块:http、server
- 该参数指定了用户请求的http头部的size大小,如果请求头部大小超过了该数值,那么就会将请求就会交由
large_client_header_buffers参数定义的buffer处理。
large_client_header_buffers- 语法:large_client_header_buffers number size;
- 默认:large_client_header_buffers 4 8k;
- 配置块:http、server
- 该参数主要是在用户的请求头部信息超过了
client_header_buffer_size所能存储的大小时使用,该参数定义了每个header所能传输的数据的大小,以及最多能够传输多少个header。如果单个header大小超限,则会返回414(Request-URI Too Large)状态码,如果是header个数超限,则会返回400(Bad Request)状态码。
Apache HTTP Server (httpd)
httpd 对请求行的默认限制为 8190 字节(比 8KB少两个字节),可以通过 LimitRequestLine 指令修改。
- Description: Limit the size of the HTTP request line that will be accepted from the client
- Syntax:
LimitRequestLinebytes - Default:
LimitRequestLine 8190 - Context: server config, virtual host
- Status: Core
- Module: core
This directive sets the number of bytes that will be allowed on the HTTP request-line.
The LimitRequestLine directive allows the server administrator to set the limit on the allowed size of a client's HTTP request-line. Since the request-line consists of the HTTP method, URI, and protocol version, the LimitRequestLine directive places a restriction on the length of a request-URI allowed for a request on the server. A server needs this value to be large enough to hold any of its resource names, including any information that might be passed in the query part of a GET request.
思考总结
一表胜千言
以上内容可以总结成一张表格:
| URL | Request Line | URL过长的结果 | |
|---|---|---|---|
| HTTP/1.1 标准 | 推荐服务端至少支持8000字节 | ||
| HTTP/2 标准 | 无限制 | ||
| URL、URI 标准 | 无限制 | ||
| Chromium | 2MB | 打开失败 | |
| Firefox | 1MB | 打开失败 | |
| Safari | 无限制 | ||
| IE8 | ~2083字节 | 打开失败 | |
| IE9-IE11 | 无限制 | ||
| Node.js >= v13.13.0 | 16KB | 抛出Header overflow异常 | |
| Node.js < v13.13.0 | 8KB | 抛出Header overflow异常 | |
| nginx | 8KB | 返回 4xx 错误 | |
| httpd | 8190字节 | 返回 4xx 错误 |
根据木桶效应,如果不考虑旧版IE,URL长度和请求头大小不应该超过 8KB。
开发注意点
针对URL和HTTP的限制,在开发过程中需要我们注意以下几点:
- 考虑 URL 长度,特别是查询参数(Query String)
- 考虑 HTTP header 数量和大小,特别是 Cookie 和鉴权使用的 token
- 考虑请求体大小,特别是大文件上传场景
- 根据实际情况调整 Node.js/nginx 等服务器默认配置
如何解决URL过长问题
- GET 请求修改成 POST 请求,将 URL 中的查询参数移到请求体中,如果单个请求体过大,进一步分片上传
- 使用无损压缩算法对 URL 参数预先压缩
- 如果是由短信、微博、即时通信工具消息长度产生的限制,可以使用短链接服务
一个使用压缩算法处理查询参数的示例
例如 Learn X In Y minutes 的 TypeScript 代码 https://learnxinyminutes.com/docs/typescript/,一共包含 7405 个字符(占用7405 字节),如果使用基于 LZ 算法的 lz-string 进行压缩,数据量可以减少到 5473 字节,压缩比 73.91%(减少 26.09% )。TypeScript Playground 和 @testing-library Playground 的代码分享功能便是通过 lz-string 实现,点击体验1、体验2。
Lempel Zip(LZ)编码是基于字典编码的压缩算法,使用其发明者的名字(Abraham Lempel 和 Jacob Ziv)命名。在通信会话的时候它将会产生一个字符串字典。如果接收和发送双方都有这样的字典,那么字符串可以由字典中的索引代替,以减少通信的数据的传输量。这种算法有不同的版本(LZ77、LZ78等)。
附录
URL 最大长度验证代码
客户端:
function createHttpURL(size, baseURL = 'http://localhost:8080') {
const url = `${baseURL}/?`;
const params = 'a'.repeat(size - url.length);
return url + params;
}
document.getElementById('http-link').href = createHttpURL(2 * 1024 * 1024);服务端:
const http = require('http');
const server = http.createServer((req, res) => {
res.setHeader('Content-Type', 'text/html');
res.end('<h1>Hello World</h1>');
});
server.on('clientError', (err, socket) => {
console.error(err);
socket.end('HTTP/1.1 400 Bad Request\r\n\r\n');
});
server.listen(8080, () => {
console.log(`Server started at http://127.0.0.1:8080`)
});node --max-http-header-size=4194304 http-server.js # 4MB相关代码已上传到 GitHub https://github.com/keqingrong/maximum-url-length-example。
在编写验证代码时,最初打算基于 Playwright/Puppeteer 自动化验证 Chrome/Firefox/Safari 的最大URL长度:
const { chromium, firefox, webkit } = require('playwright-core');
const browser = await firefox.launch(); // Or 'firefox' or 'webkit'.
const page = await browser.newPage();
await page.goto(url);不幸的是,Node.js 中无论是 child_process.spawn() 还是 child_process.exec() 对命令行参数都有长度限制,参数列表一旦超过 1024 个字节,则会报 Error: spawn E2BIG 错误。
Q&A
感谢阅读,如果文章中存在错误,欢迎指正。